![]()
Optuna:一个超参数优化框架
Optuna 是一个自动超参数优化软件框架,专为机器学习而设计。它具有命令式的define-by-run风格用户 API。得益于我们的define-by-run API,使用 Optuna 编写的代码具有高度模块化,并且 Optuna 用户可以动态构建超参数的搜索空间。
主要特性
Optuna 具有以下现代功能:
-
通过简单的安装即可处理各种任务,且依赖项少。
-
使用熟悉的 Python 语法定义搜索空间,包括条件语句和循环。
-
采用最先进的算法对超参数进行采样并有效地剪枝掉无希望的试验。
-
只需很少或无需更改代码即可将研究扩展到数十或数百个工作节点。
-
通过各种绘图功能查看优化历史。
基本概念
我们使用术语study(研究)和trial(试验)如下:
研究:基于目标函数的优化过程
试验:目标函数的单次执行
请参考下面的示例代码。一个study(研究)的目标是通过多次trial(试验)(例如 n_trials=100)找到最优的超参数值集合(例如 classifier 和 svm_c)。Optuna 是一个旨在自动化和加速优化studies(研究)的框架。
![]()
import ...
# Define an objective function to be minimized.
def objective(trial):
# Invoke suggest methods of a Trial object to generate hyperparameters.
regressor_name = trial.suggest_categorical('classifier', ['SVR', 'RandomForest'])
if regressor_name == 'SVR':
svr_c = trial.suggest_float('svr_c', 1e-10, 1e10, log=True)
regressor_obj = sklearn.svm.SVR(C=svr_c)
else:
rf_max_depth = trial.suggest_int('rf_max_depth', 2, 32)
regressor_obj = sklearn.ensemble.RandomForestRegressor(max_depth=rf_max_depth)
X, y = sklearn.datasets.fetch_california_housing(return_X_y=True)
X_train, X_val, y_train, y_val = sklearn.model_selection.train_test_split(X, y, random_state=0)
regressor_obj.fit(X_train, y_train)
y_pred = regressor_obj.predict(X_val)
error = sklearn.metrics.mean_squared_error(y_val, y_pred)
return error # An objective value linked with the Trial object.
study = optuna.create_study() # Create a new study.
study.optimize(objective, n_trials=100) # Invoke optimization of the objective function.
Web 仪表盘
Optuna Dashboard 是一个 Optuna 的实时 Web 仪表盘。您可以在图表和表格中查看优化历史、超参数重要性等。您无需创建 Python 脚本来调用 Optuna 的可视化功能。欢迎提出功能请求和报告错误!
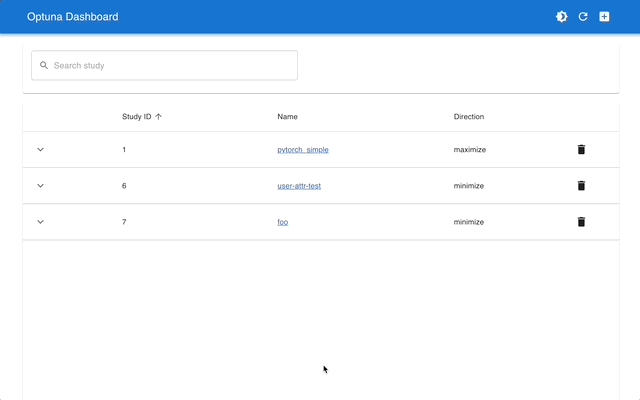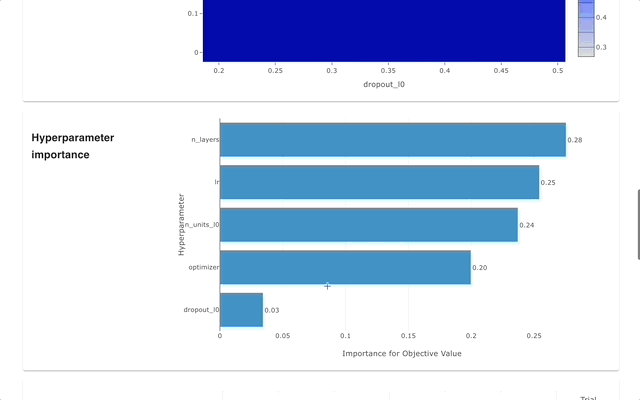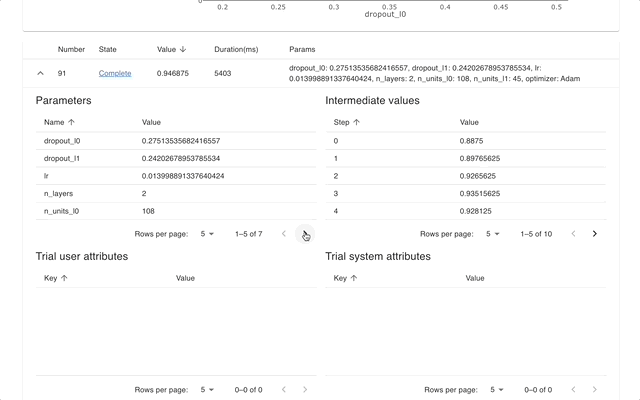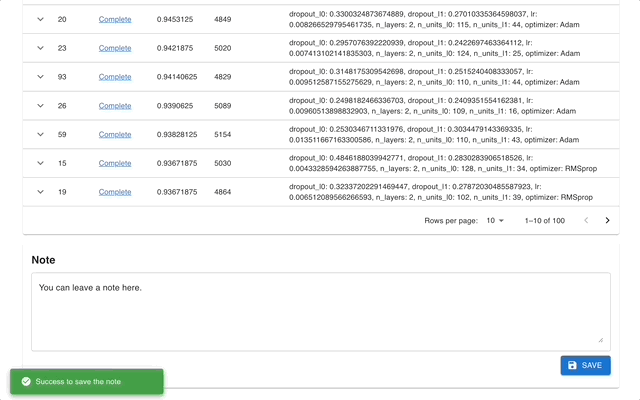
可以通过 pip 安装 optuna-dashboard
$ pip install optuna-dashboard
提示
请查阅 Optuna Dashboard 官方文档的入门部分。
交流
有问题请访问GitHub Discussions。
报告错误和提出功能请求请访问GitHub Issues。
贡献
欢迎对 Optuna 作出任何贡献!提交拉取请求时,请遵循贡献指南。
许可协议
MIT 许可协议(参见 LICENSE)。
Optuna 使用了 SciPy 和 fdlibm 项目的代码(参见第三方许可)。
参考
Takuya Akiba, Shotaro Sano, Toshihiko Yanase, Takeru Ohta, and Masanori Koyama. 2019. Optuna: 一个下一代超参数优化框架。收录于 KDD (arXiv)。
目录
- 安装
- 教程
- API 参考
- 常见问题
- 我可以将 Optuna 与 X 一起使用吗?(其中 X 是您喜欢的机器学习库)
- 如何定义带有自己参数的目标函数?
- 我可以在没有远程 RDB 服务器的情况下使用 Optuna 吗?
- 如何保存和恢复研究?
- 如何抑制 Optuna 的日志消息?
- 如何保存目标函数中训练的机器学习模型?
- 如何获得可重现的优化结果?
- 如何处理试验中的异常?
- 如何处理试验返回的 NaN 值?
- 动态修改搜索空间时会发生什么?
- 如何使用两个 GPU 同时评估两个试验?
- 如何测试我的目标函数?
- 在优化研究时如何避免内存不足(OOM)?
- 如何仅在最佳值更新时输出日志?
- 如何建议表示比例的变量,即符合狄利克雷分布的变量?
- 如何优化带有约束的模型?
- 如何并行化优化?
- 如何解决使用 SQLite3 进行并行优化时发生的错误?
- 我可以监控试验并在它们意外终止时自动标记为失败吗?
- 如何处理作为参数的排列?
- 如何忽略重复的样本?
- 如何删除上传到研究的所有工件?